The viral epidemics are a severe threat to the entire world. It's causing the significant loss, but COVID is not the first one, and it's not the last one too. The promising hope to this, Humanity has so far survived every microbe we came across, and human species will survive this one also.
If the history is repeating, what differs from previous epidemics? The answer is Data. Yes, saying again - Data. The recent innovations and infrastructure facilitate dealing with the massive amount of data to analyze. We are collecting and sharing what we learn about the virus, identify who is at more risk, locations to track contacts, wearable technologies to monitor vitals, our behaviors that cause the terrible spread pattern, and more including predicting the next pandemic.
As we gather an enormous amount of data, Machine Learning plays a crucial role in analyzing the data, train the model to predict the risks with high accuracy. Hear more from Geekwire Health Tech podcast on how AI is helping in the fight against COVID'19. {% spotify spotify:episode:5JxnMVcHLX8Pb8ZFS2OO3a %}
Face Touch - Warning System
Let me explain why I want to create a warning system against face touching personally. One of the COVID'19 prevention advice is to avoid touching the face. Face touching is an automatic reflex. It's tough to avoid touching. Notably, the one wearing correction glasses like me can easily relate them on face touching.
So I decided to build the ML model using Google Cloud AutoML Vision, which alerts me when I'm going to touch my face. In this blog series, I will explain the steps to build the model and do high-quality inference using Tensorflow JS and also in Raspberry Pi using Edge TPU.
Google Cloud AutoML Vision
Google Cloud AutoML Vision enables developers with limited machine learning expertise to train high-quality models specific to your business needs. It relies on Google's state-of-the-art transfer learning and neural architecture search technology to find the best network architecture and the optimal hyperparameter configuration that minimizes the loss function of the model.
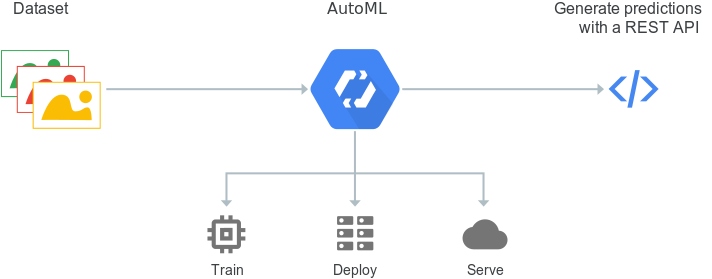
Steps to create an image classification model using AutoML Vision API:
- Data preparation and labeling
- Training the model
- Evaluate
- Deploying models in the cloud / Exporting your models to use in Edge.
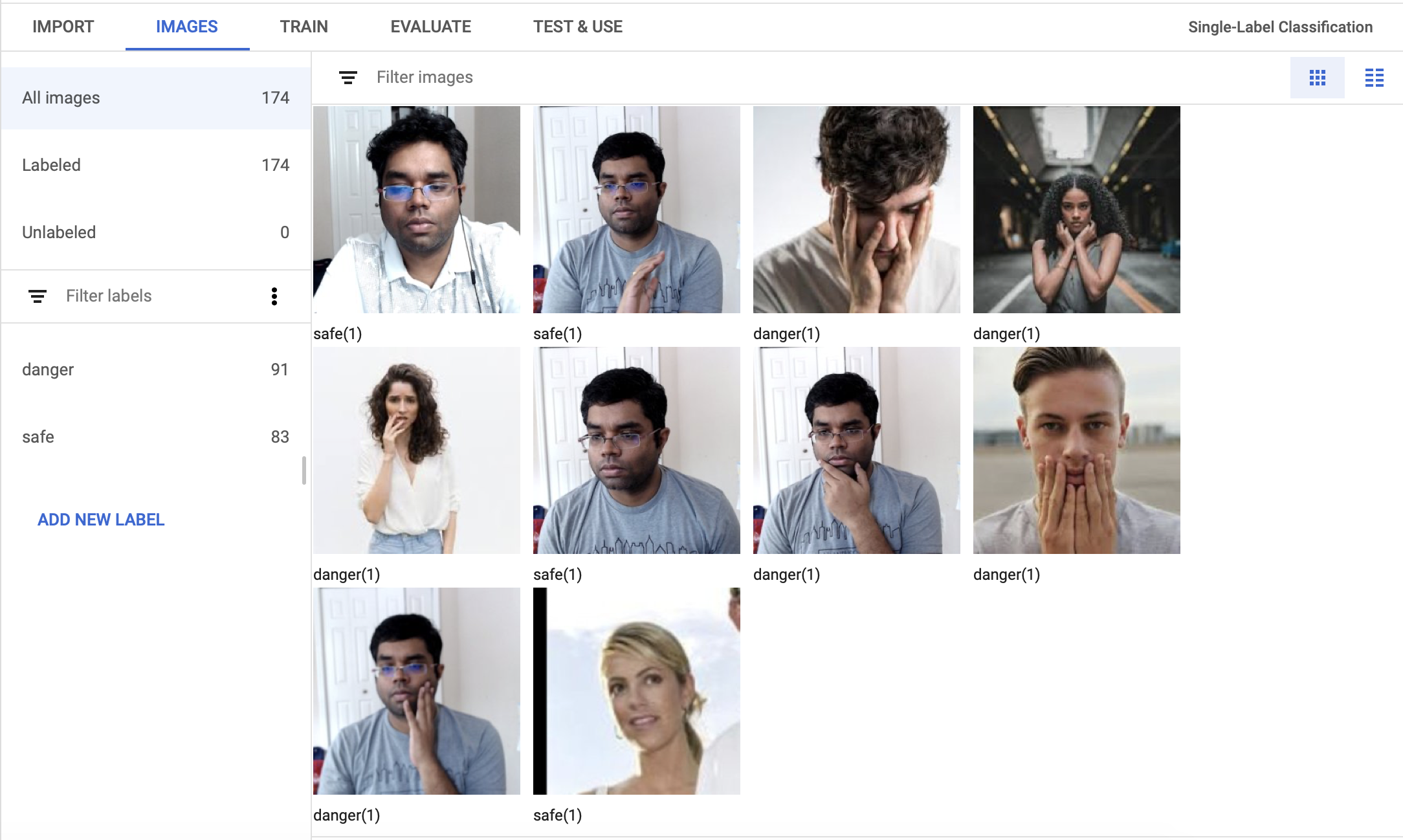
Data preparation
I've taken pictures of my family and me under two significant categories. One with touching the face and another one without touching the face. Later, I've added more different faces under these labels from the public datasets such as [Open Image Dataset] (https://opensource.google/projects/open-images-dataset) and Kaggle
Training the model
Now it's time to train the model. Click on the Train tab and start training.
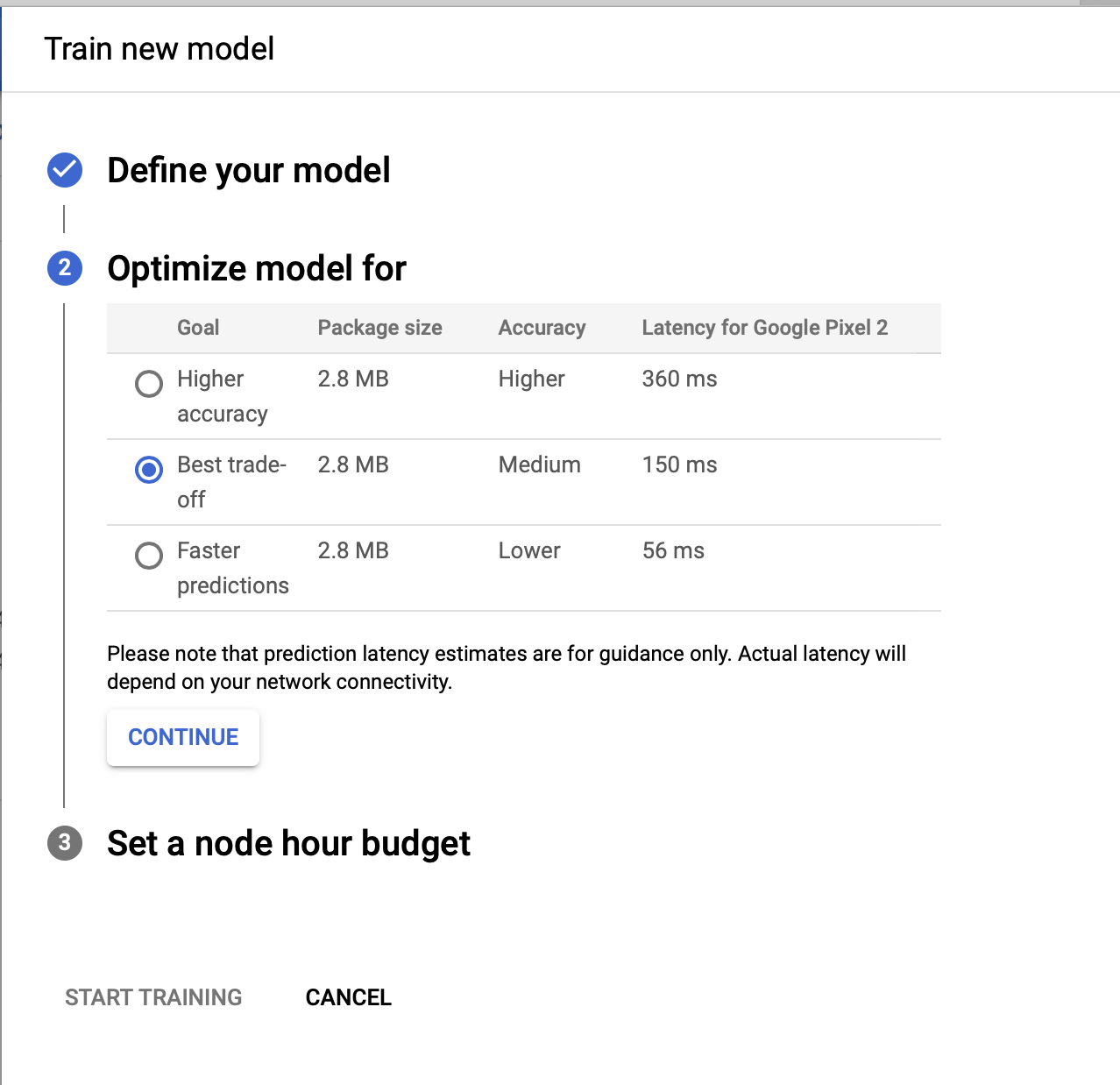
When you start training, you need to provide the below settings
- Model Name - Name of the model
- Type - the model type you want to train
- Cloud-hosted for online prediction
- Edge for device and offline use.
- Model Optimization Type - If you are training for the edge, choose the optimization type higher accuracy or best trade-off or fast predictions with low accuracy
- Node hours - Enter the maximum number of node hours you want to spend training your model.
Google Cloud recommends using 3 node hours for your dataset. However, the model training process now stops earlier by default when the search process is no longer finding better performing models. In this case, it took 0.264 hours to train the model, even though I specified 3 node hours for the budget.
Evaluate
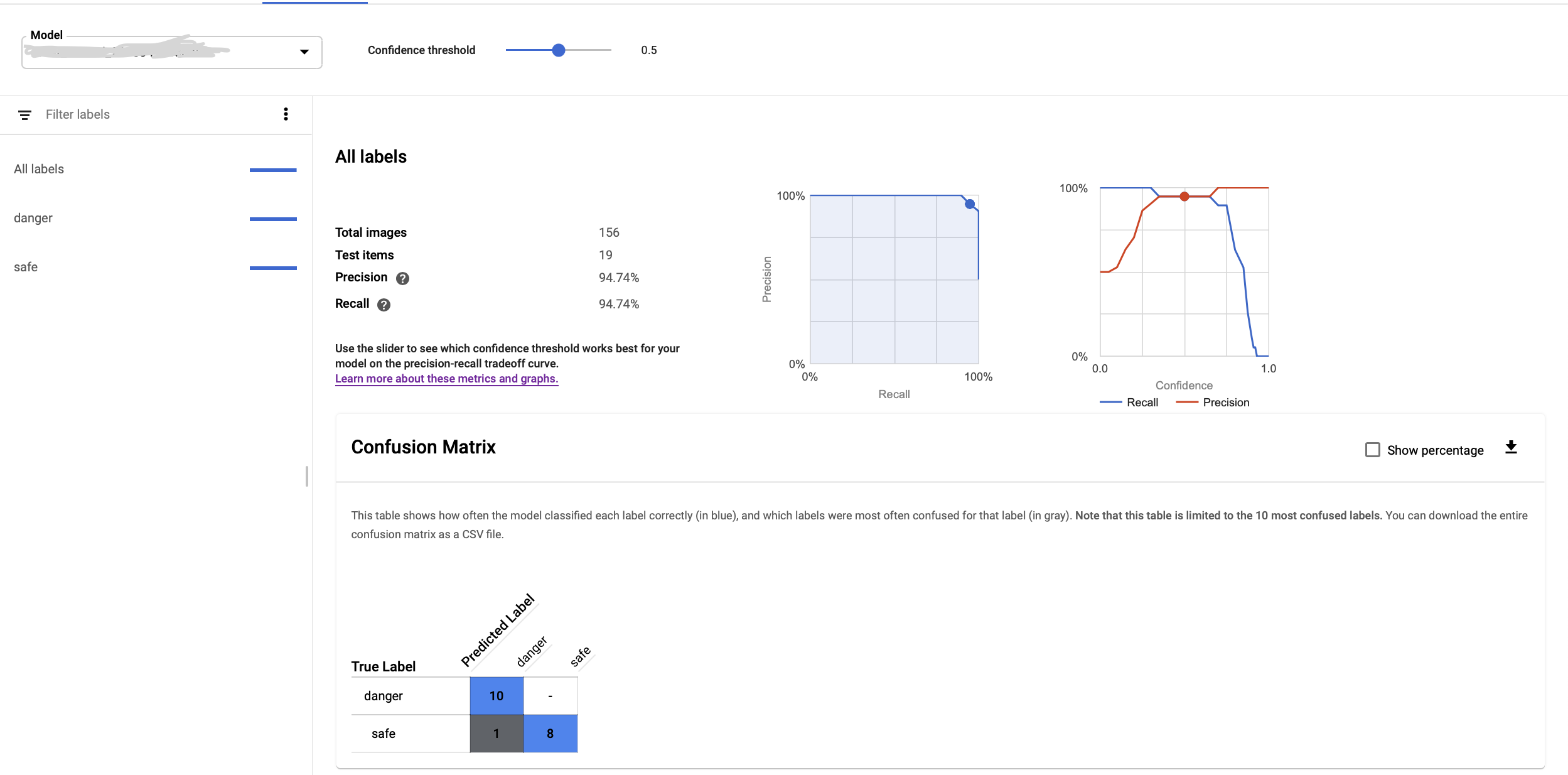
Once the model is trained, navigate to the Evaluate tab to explore the analysis of the trained model and precision/recall percentages. You can drag the score threshold slider to adjust the precision-recall tradeoff. The confusion matrix explains how often the model classified each label correctly (in blue), and which labels were most often confused for that label. You can analyze the confusion matrix and modify the dataset to train further to avoid false positives and false negatives on prediction.
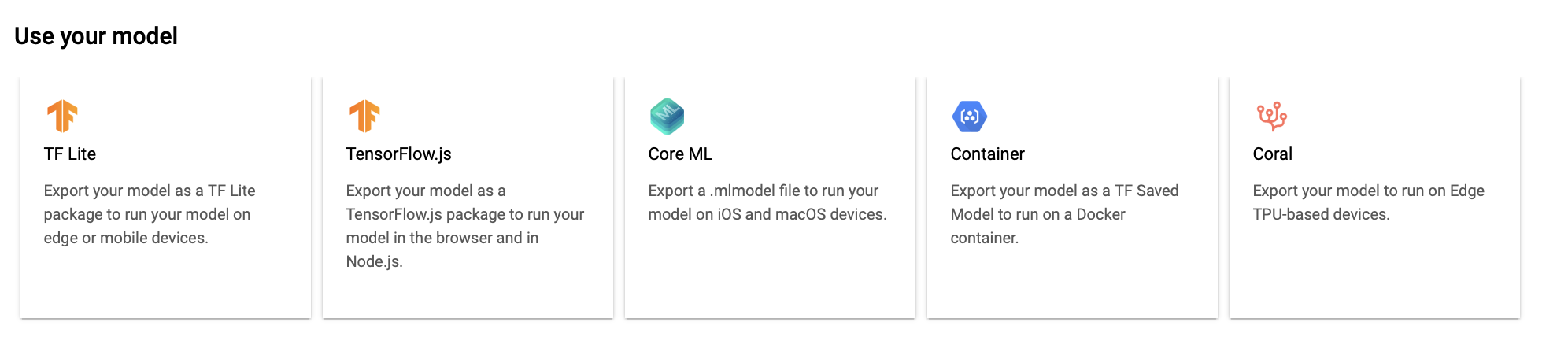
Exporting your models to use in Edge
After you have trained a model, you can export your custom model to predict on your edge devices. After exporting your model, you can then deploy the model to a device.
You can export an image classification model in either generic Tensorflow Lite format, general TensorFlow format, or TensorFlow.js for Web format and CoreML. It also supports to run the model predictions on Google Coral USB Accelerator, and containers.
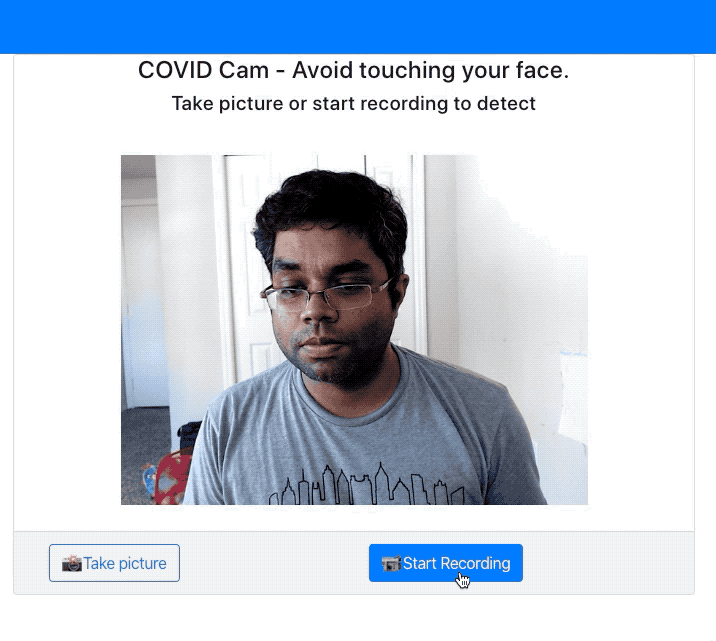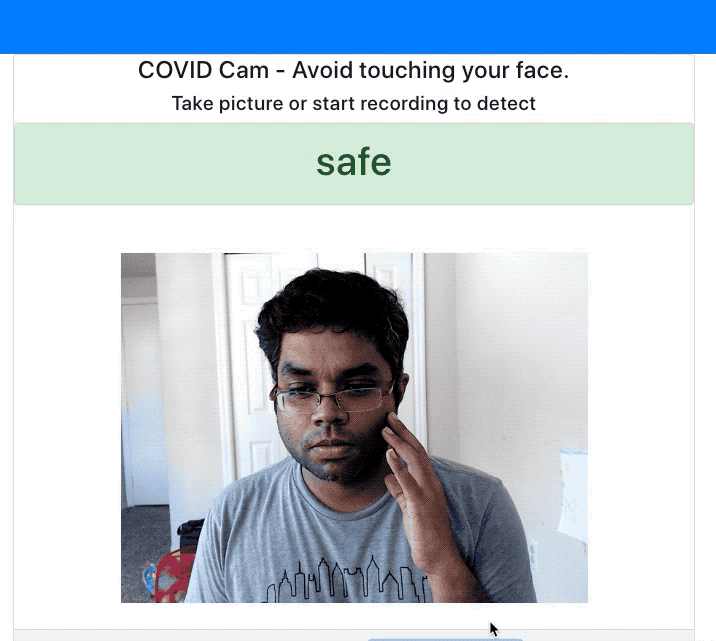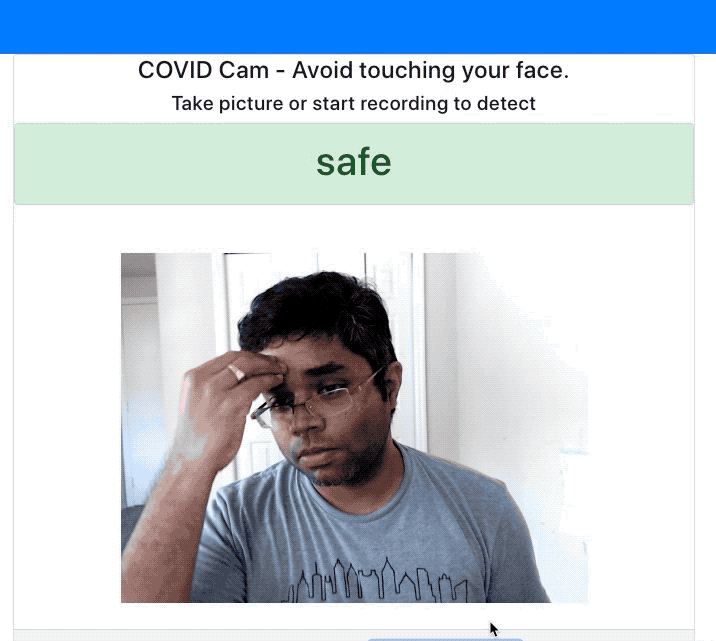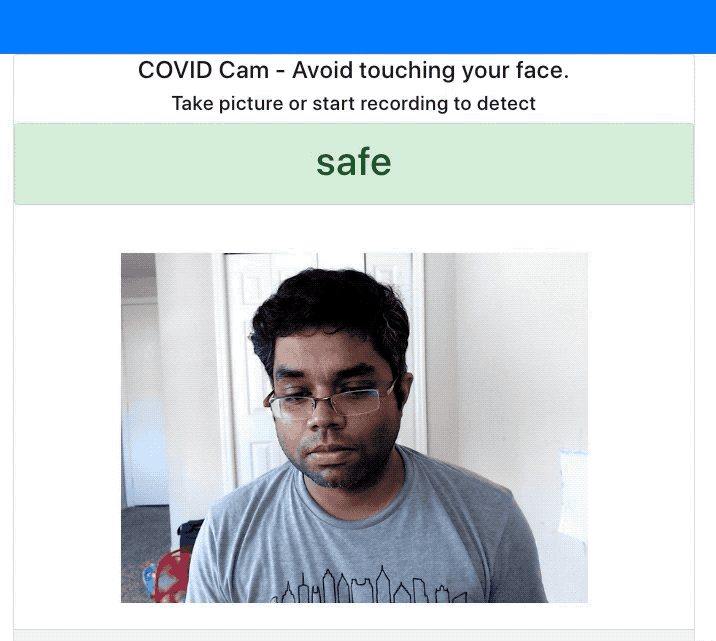
Demo
I've exported this model to Tensorflow.js format to make the predictions on the website. See the below demo where it alerts me when I'm touching my face.
Conclusion
This article provided a walkthrough to design powerful vision models for custom use-cases by leveraging Google Cloud Platform AutoML Vision. It's a great tool to quickly prototype and builds image classification and object detection uses-cases with AutoML capabilities.
I will cover how to run the predictions using Tensorflow.js to run on the web browser and also how to run the inference pretty fast using Raspberry PI and Coral USB Edge TPU Accelerator in the next post of this series.
Do you want to see the demo live? I'm going to present this demo at GDG Central Florida + Orlando IoT Virtual Meetup on April 15, 2020 - 6.30 pm ET. The event is streaming live at Orlando IoT Youtube Channel
We don't want to stop learning, sharing, and being a community in tough times. Everyone, stay safe and healthy. Please do like, share and comment. DM me at my twitter @ksivamuthu if you've any questions or to discuss ML/IoT use cases for your business to solve.